Compilation
In order to run the OpenACC port of VASP 6, it must be compiled with NVIDIA's HPC-SDK toolkit. On IT4I systems, this toolkit is available within the NVHPC module.
Version 20.9 of the HPC-SDK is the latest officially confirmed version to work with VASP 6.x.x, but I've had a good experience even with version 21.2.
VASP wiki provides a makefile.include either for OpenMP version or for serial MKL version. The OpenMP version should provide increased performance.
To adapt the makefile.include, I needed to tweak a path to the libiomp5.so library. Additionally, one can encounter an issue, where libqd.so and libqdmod.so cannot be found at runtime. This is caused by the NVHPC module not containing the path to these two libraries and it can be solved either by linking these libraries statically or by adding the path into the LD_LIBRARY_PATH.
Additionally, one should make sure that the compute capability is set accordingly. Tesla V100 GPUs on Barbora cluster are compatible with compute capability of 70.
FC = mpif90 -acc -gpu=cc70,cuda11.0 -mp
FCL = mpif90 -acc -gpu=cc70,cuda11.0 -c++libs -mpThere are other flags needed to compile the OpenACC port of VASP 6, but these should be supplied in the makefile.include file by default.
The VASP binary versions to be compiled are vasp_std, vasp_gam and/or vasp_ncl (i.e. $ make std gam ncl).
Note: libqd.so/.a and libqdmod.so/.a at IT4I are located in the /apps/all/NVHPC/<HPC-SDK-version>/Linux_x86_64/<HPC-SDK-version>/compilers/extras/qd/lib/ directory.
Note: The vasp_gpu and vasp_gpu_ncl binaries are meant for the deprecated CUDA GPU port. They should not be compiled for the OpenACC port.
Execution
The usage of the OpenACC port is exactly the same as with CPU version. You run
$ mpirun vasp_stdor any equivalent form of this command.
One thing to keep in mind is to set the correct number of OpenMP threads and the number of MPI ranks per node. On Barbora's GPU nodes, there are 4 GPUs on each node. This translates to 4 MPI ranks per node. Multiple processes (MPI ranks) on a single GPU are not supported. There are also 24 CPU cores on each of Barbora's GPU nodes. If one uses the OpenMP version of the OpenACC port, he/she should specify the number of OpenMP threads to be 6. For the serial version, the number of OpenMP threads will always be 1.
The following snippets from a jobscript are meant for PBS scheduler, which is used at IT4I clusters.
OpenMP version:
#PBS -l select=<number-nodes>:ncpus=24:mpiprocs=4:ompthreads=6Serial Version:
#PBS -l select=<number-nodes>:ncpus=24:mpiprocs=4:ompthreads=1Note: Correct number of OpenMP threads can also be set by setting the value to the environment variable OMP_NUM_THREADS before executing VASP.
Note: When using the serial version, only 4 out of the 24 CPUs will be used.
Performance (GPU vs CPU)
Important: There currently seems to be a bug, either in my compilation or in the used toolchain or on the cluster, which prevents VASP from running to completion when executed on more than one GPU node on Barbora. Comparison of multi-node jobs will get corrected as soon as this bug is resolved. Take the depicted performance on 2 nodes with a grain of salt. However the performance difference on 1 node between CPUs and GPUs should be taken very seriously.
Note: the GPU version was not yet tested on 4 nodes due to the bug.
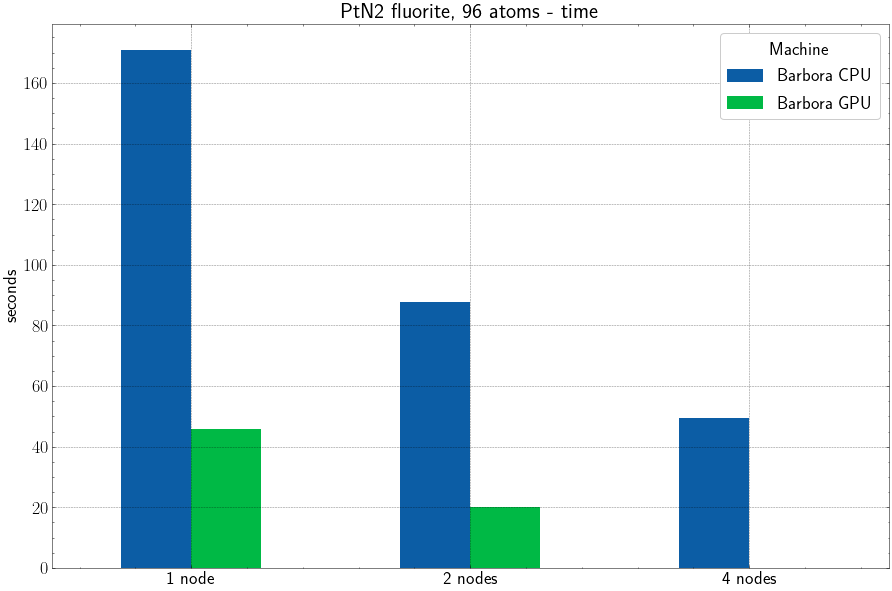
The plot above shows an average time per one iteration of the test case.
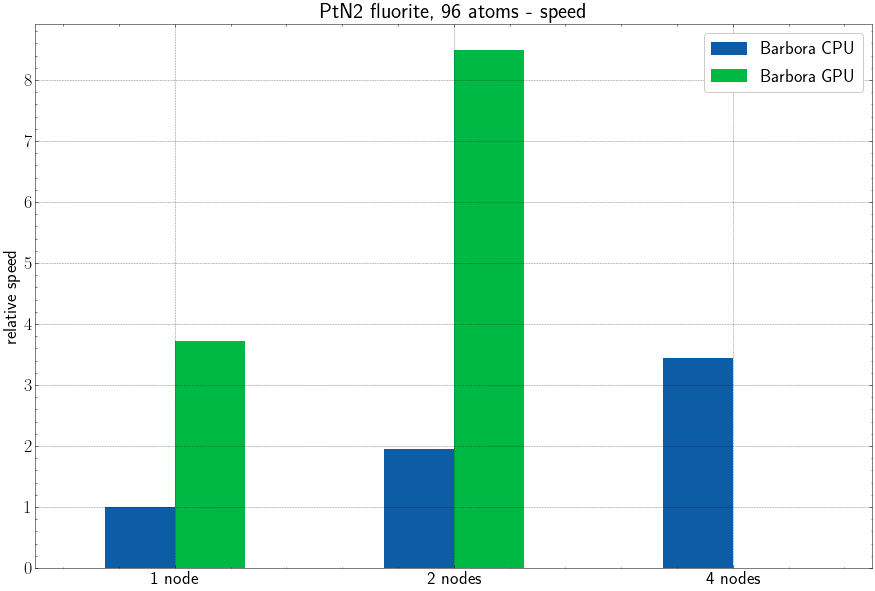
This plot shows relative performance, which is derived from the time plot.
The CPU calculations were ran using the rules described in the article Scaling of VASP 5 on IT4Innovations clusters – metallic structure, i.e. KPAR = 2 * <number-of-nodes>, NCORE = 18, NSIM = 4.
Jobs on GPUs performed very similarly when KPAR = <number-of-nodes> and KPAR = 2 * <number-of-nodes>. NSIM = 16 provided additional speedup, however at NSIM >= 64, the calculations started to slow down again.
The limiting factor for running calculation on Barbora's GPU nodes is the amount of available graphical memory. The 96 atoms test case could only use KPAR = 2 * <number-of-nodes> at most. Theoretically, using KPAR = 4 * <number-of-nodes> ( = <total-number-of-GPUs>) might have been faster, if it fitted into the GPU memory.
Conclusion
GPU version of VASP 6 is much more powerful and easy to use than VASP 5 CUDA port. With these tests, we hope to demonstrate the usefulness of the OpenACC port for greatly speeding up your calculations. Furthermore, the accounting factor (per whole node) for Barbora's GPU nodes is only about two times the accounting factor of the CPU nodes. This means, that running calculations there is not only about 4 times faster, but also about 2 times cheaper, relative to Barbora's CPU nodes.
That being said, there is still the aforementioned issue with running the GPU port on multiple nodes. That however should get resolved soon.